
ZFS Administration - Appendix A - Visualizing The ZFS Intent LOG (ZIL)
Background
While taking a walk around the city with the rest of the system administration team at work today (we have our daily "admin walk"), a discussion came up about asynchronous writes and the contents of the ZFS Intent Log. Previously, as shown in the Table of Contents, I blogged about the ZIL in great length. However, I didn't really discuss what the contents of the ZIL were, and to be honest, I didn't fully understand it myself. Thanks to Andrew Kuhnhausen, this was clarified. So, based on the discussion we had during our walk, as well as some pretty graphs on the whiteboard, I'll give you the breakdown here.
Let's start at the beginning. ZFS behaves more like an ACID compliant RDBMS than a traditional filesystem. Its writes are transactions, meaning there are no partial writes, and they are fully atomic, meaning you get all or nothing. This is true whether the write is synchronous or asynchronous. So, best case is you have all of your data. Worst case is you missed the last transactional write, and your data is 5 seconds old (by default). So, let's look at those too cases- the synchronous write and the asynchronous write. With synchronous, we'll consider the write both with and without a separate logging device (SLOG).
The ZIL Function
The primary, and only function of the ZIL is to replay lost transactions in the event of a failure. When a power outage, crash, or other catastrophic failure occurs, pending transactions in RAM may have not been committed to slow platter disk. So, when the system recovers, the ZFS will notice the missing transactions. At this point, the ZIL is read to replay those transactions, and commit the data to stable storage. While the system is up and running, the ZIL is never read. It is only written to. You can verify this by doing the following (assuming you have SLOG in your system). Pull up two terminals. In one terminal, run an IOZone benchmark. Do something like the following:
This will run a whole series of tests to see how your disks perform. While this benchmark is running, in the other terminal, as root, run the following command:
This will clearly show you that when the ZIL resides on a SLOG, the SLOG devices are only written to. You never see any numbers in the read columns. This is becaus the ZIL is never read, unless the need to replay transactions from a crash are necessary. Here is one of those seconds illustrating the write:
pool alloc free read write read write
------------------------------------------------------- ----- ----- ----- ----- ----- -----
pool 87.7G 126G 0 155 0 601K
mirror 87.7G 126G 0 138 0 397K
scsi-SATA_WDC_WD2500AAKX-_WD-WCAYU9421741-part5 - - 0 69 0 727K
scsi-SATA_WDC_WD2500AAKX-_WD-WCAYU9755779-part5 - - 0 68 0 727K
logs - - - - - -
mirror 2.43M 478M 0 8 0 108K
scsi-SATA_OCZ-REVODRIVE_XOCZ-6G9S9B5XDR534931-part1 - - 0 8 0 108K
scsi-SATA_OCZ-REVODRIVE_XOCZ-THM0SU3H89T5XGR1-part1 - - 0 8 0 108K
mirror 2.57M 477M 0 7 0 95.9K
scsi-SATA_OCZ-REVODRIVE_XOCZ-V402GS0LRN721LK5-part1 - - 0 7 0 95.9K
scsi-SATA_OCZ-REVODRIVE_XOCZ-WI4ZOY2555CH3239-part1 - - 0 7 0 95.9K
cache - - - - - -
scsi-SATA_OCZ-REVODRIVE_XOCZ-6G9S9B5XDR534931-part5 26.6G 56.7G 0 0 0 0
scsi-SATA_OCZ-REVODRIVE_XOCZ-THM0SU3H89T5XGR1-part5 26.5G 56.8G 0 0 0 0
scsi-SATA_OCZ-REVODRIVE_XOCZ-V402GS0LRN721LK5-part5 26.7G 56.7G 0 0 0 0
scsi-SATA_OCZ-REVODRIVE_XOCZ-WI4ZOY2555CH3239-part5 26.7G 56.7G 0 0 0 0
------------------------------------------------------- ----- ----- ----- ----- ----- -----
The ZIL should always be on non-volatile stable storage! You want your data to remain consistent across power outages. Putting your ZIL on a SLOG that is built from TMPFS, RAMFS, or RAM drives that are not battery backed means you will lose any pending transactions. This doesn't mean you'll have corrupted data. It only means you'll have old data. With the ZIL on volatile storage, you'll never be able to get the new data that was pending a write to stable storage. Depending on how busy your servers are, this could be a Big Deal. SSDs, such as from Intel or OCZ, are good cheap ways to have a fast, low latentcy SLOG that is reliable when power is cut.
Synchronous Writes without a SLOG
When you do not have a SLOG, the application only interfaces with RAM and slow platter disk. As previously discussed, the ZFS Intent LOG (ZIL) can be thought of as a file that resides on the slow platter disk. When the application needs to make a synchronous write, the contents of that write are sent to RAM, where the application is currently living, as well as sent to the ZIL. So, the data blocks of your synchronous write at this exact moment in time have two homes- RAM and the ZIL. Once the data has been written to the ZIL, the platter disk sends an acknowledgement back to the application letting it know that it has the data, at which point the data is flushed from RAM to slow platter disk.
This isn't ALWAYS the case, however. In the case of slow platter disk, ZFS can actually store the transaction group (TXG) on platter immediately, with pointers in the ZIL to the locations on platter. When the disk ACKs back that the ZIL contains the pointers to the data, then the write TXG is closed in RAM, and the space in the ZIL opened up for future transactions. So, in essence, you could think of the TXG SYNCHRONOUS write commit happening in three ways:
- All data blocks are synchronously written to both the RAM ARC and the ZIL.
- All data blocks are synchronously written to both the RAM ARC and the VDEV, with pointers to the blocks written in the ZIL.
- All data blocks are synchronously written to disk, where the ZIL is completely ignored.
In the image below, I tried to capture a simplified view of the first process. The pink arrows, labeled as number one, show the application committing its data to both RAM and the ZIL. Technically, the application is running in RAM already, but I took it out to make the image a bit more clean. After the blocks have been committed to RAM, the platter ACKs the write to the ZIL, noted by the green arrow labeled as number two. Finally, ZFS flushes the data blocks out of RAM to disk as noted by the gray arrow labeled as number three.
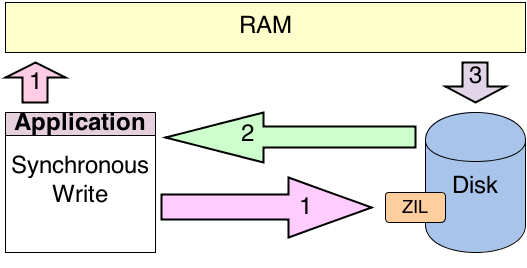
Image showing a synchronous write with ZFS without a SLOG
Synchronous Writes with a SLOG
The advantage of a SLOG, as previously outlined, is the ability to use low latency, fast disk to send the ACK back to the application. Notice that the ZIL now resides on the SLOG, and no longer resides on platter. The SLOG will catch all synchronous writes (well those called with O_SYNC and fsync(2) at least). Just as with platter disk, the ZIL will contain the data blocks the application is trying to commit to stable storage. However, the SLOG, being a fast SSD or NVRAM drive, ACKs the write to the ZIL, at which point ZFS flushes the data out of RAM to slow platter.
Notice that ZFS is not flushing the data out of the ZIL to platter. This is what confused me at first. The data is flushed from RAM to platter. Just like an ACID compliant RDBMS, the ZIL is only there to replay the transaction, should a failure occur, and the data is lost. Otherwise, the data is never read from the ZIL. So really, the write operation doesn't change at all. Only the location of the ZIL changes. Otherwise, the operation is exactly the same.
As shown in the image, again the pink arrows labeled number one show the application committing its data to both the RAM and the ZIL on the SLOG. The SLOG ACKs the write, as identified by the green arrow labeled number two, then ZFS flushes the data out of RAM to platter as identified by the gray arrow labeled number three.
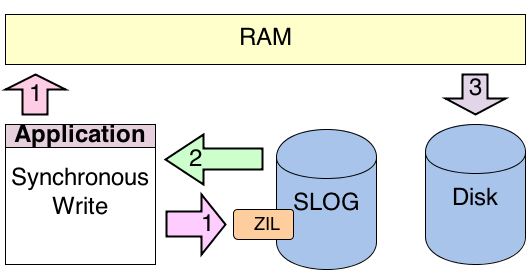
Image showing a synchronous write with ZFS with a SLOG
Asynchronous Writes
Asynchronous writes have a history of being "unstable". You have been taught that you should avoid asynchronous writes, and if you decide to go down that path, you should prepare for corrupted data in the event of a failure. For most filesystems, there is good counsel there. However, with ZFS, it's a nothing to be afraid of. Because of the architectural design of ZFS, all data is committed to disk in transaction groups. Further, the transactions are atomic, meaning you get it all, or you get none. You never get partial writes. This is true with asynchronous writes. So, your data is ALWAYS consistent on disk- even with asynchronous writes.
So, if that's the case, then what exactly is going on? Well, there actually resides a ZIL in RAM when you enable "sync=disabled" on your dataset. As is standard with the previous synchronous architectures, the data blocks of the application are sent to a ZIL located in RAM. As soon as the data is in the ZIL, RAM acknowledges the write, and then flushes the data do disk, as would be standard with synchronous data.
I know what you're thinking: "Now wait a minute! The are no acknowledgements with asynchronous writes!" Not always true. With ZFS, there is most certainly an acknowledgement, it's just one coming from very, very fast and extremely low latent volatile storage. The ACK is near instantaneous. Should there be a crash or some other failure that causes RAM to lose power, and the write was not saved to non-volatile storage, then the write is lost. However, all this means is you lost new data, and you're stuck with old but consistent data. Remember, with ZFS, data is committed in atomic transactions.
The image below illustrates an asynchronous write. Again, the pink number one arrow shows the application data blocks being initially written to the ZIL in RAM. RAM ACKs back with the green number two arrow. ZFS then flushes the data to disk, as per every previous implementation, as noted by the gray number 3 arrow. Notice in this image, even if you have a SLOG, with asynchronous writes, it's bypassed, and never used.

Image showing an asynchronous write with ZFS.
Disclaimer
This is how I and my coworkers understand the ZIL. This is after reading loads of documentation, understanding a bit of computer science theory, and understanding how an ACID compliant RDBMS works, which is architected in a similar manner. If you think this is not correct, please let me know in the comments, and we can have a discussion about the architecture.
There are certainly some details I am glossing over, such as how much data the ZIL will hold before its no longer utilized, timing of the transaction group writes, and other things. However, it should also be noted that aside from some obscure documentation, there doesn't seem to be any solid examples of exactly how the ZIL functions. So, I thought it would be best to illustrate that here, so others aren't left confused like I was. For me, images always make things clearer to understand.
Posted by Aaron Toponce on Friday, April 19, 2013, at 5:00 am.
Filed under Debian, Linux, Ubuntu, ZFS.
Follow any responses to this post with its comments RSS feed.
You can post a comment or trackback from your blog.
For IM, Email or Microblogs, here is the Shortlink.